
What is Load Balancing? - Definition & Meaning
Load balancing distributes incoming traffic across multiple servers so no single system gets overloaded. It is the foundation for high availability.
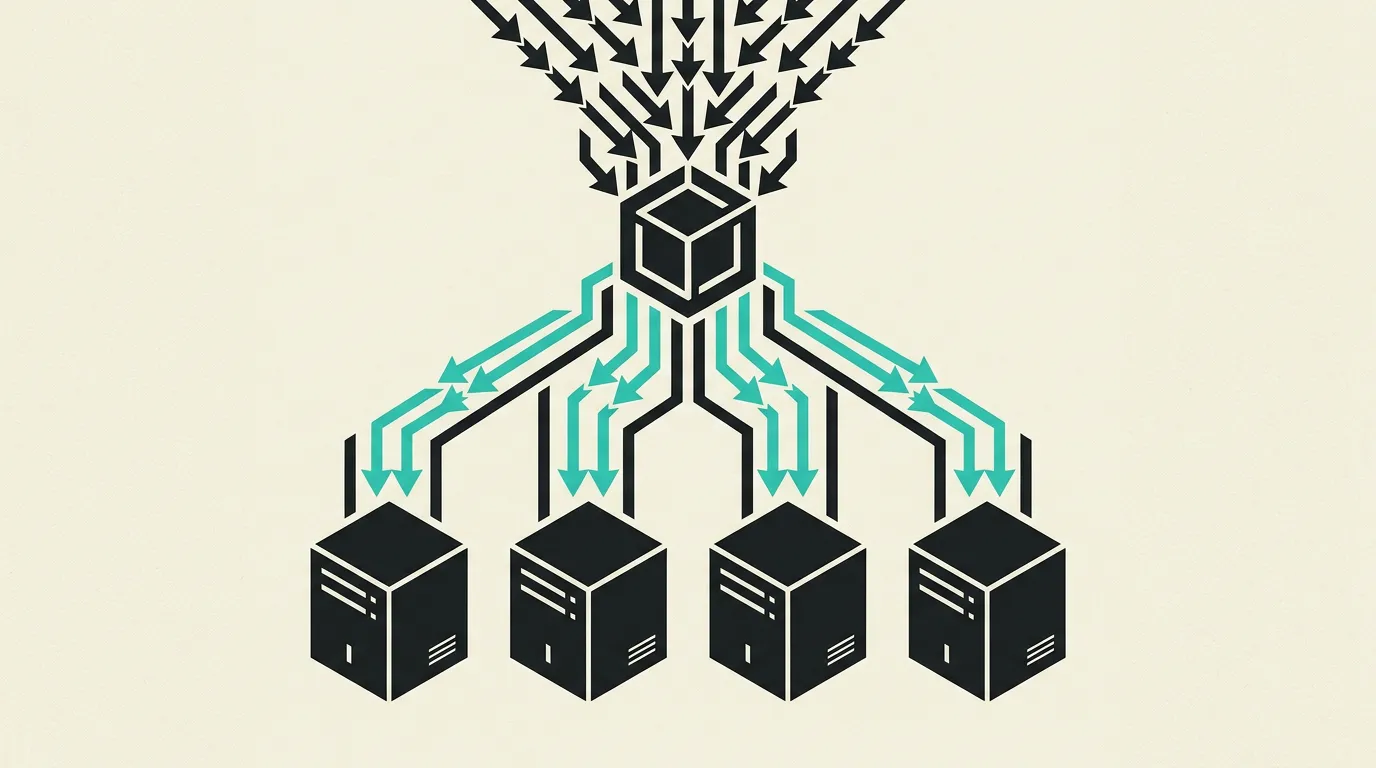
Load balancing is the distribution of incoming network traffic across multiple servers to spread the workload evenly and eliminate single points of failure. This significantly improves the availability, reliability, and performance of applications. A load balancer acts as a traffic controller that intercepts requests and forwards them to the most suitable backend server based on health status, available capacity, and configured routing rules.
What is Load Balancing?
Load balancing is the distribution of incoming network traffic across multiple servers to spread the workload evenly and eliminate single points of failure. This significantly improves the availability, reliability, and performance of applications. A load balancer acts as a traffic controller that intercepts requests and forwards them to the most suitable backend server based on health status, available capacity, and configured routing rules.
How does Load Balancing work technically?
Load balancers operate at different OSI layers: Layer 4 (transport) distributes traffic based on IP and TCP/UDP port without inspecting packet content, resulting in very low latency overhead. Layer 7 (application) makes content-aware decisions based on HTTP headers, URL paths, cookies, or even request body, enabling advanced routing scenarios. Common algorithms include round-robin (distributing requests evenly in fixed order), least connections (routing to the server with fewest active connections), weighted round-robin (servers with more capacity receive proportionally more traffic), IP hash (consistent routing based on client IP for session affinity), and least response time (routing to the server with the fastest response). Health checks continuously monitor backend server health via HTTP endpoints, TCP checks, or custom scripts; unhealthy servers are automatically removed from the pool and re-added once they recover. Session persistence (sticky sessions) ensures a user is always routed to the same server, necessary when session state lives locally on the server. NGINX and HAProxy are popular software-based load balancers with extensive configuration options. Cloud providers offer managed solutions such as AWS ALB/NLB, Google Cloud Load Balancer, and Azure Load Balancer with built-in autoscaling and health monitoring. SSL termination at the load balancer reduces cryptographic overhead on backend servers by handling TLS handshakes centrally. Auto-scaling groups coupled with load balancers automatically add servers during traffic increases and remove them when the spike passes, optimizing costs. Global Server Load Balancing (GSLB) distributes traffic across multiple data centers or regions via DNS-based routing, automatically directing users to the nearest cluster for lower latency and higher availability during regional outages. Canary deployments become possible by sending a small percentage of traffic via weighted routing to a new application version, so errors can be detected before all users are affected. PROXY Protocol (v1/v2) preserves the original client IP address through the entire chain of load balancers and reverse proxies, which is essential for accurate geolocation, access logging, and rate limiting on the actual source address. WebSocket-aware load balancers keep long-lived connections intact through connection upgrade detection and prevent idle timeouts from prematurely terminating them.
How does MG Software apply Load Balancing in practice?
MG Software implements load balancing across all client production environments. We use NGINX as a reverse proxy and load balancer for web applications, and cloud-native load balancers with Vercel and AWS. For Kubernetes deployments, we configure Ingress controllers that intelligently distribute traffic across pods. We set up health checks at the application level (not just TCP) so that servers that hang but remain reachable are automatically taken out of rotation. SSL termination happens at the load balancer, after which internal traffic flows over a trusted network. This ensures our client applications remain available during traffic spikes, deployments, and maintenance windows. We implement canary deployments via weighted routing, initially directing five percent of traffic to a new version while monitoring error rates and latency before rolling out fully. Connection draining is configured by default with a 30-second timeout so in-flight requests always complete gracefully, even during rolling updates in Kubernetes, preventing errors visible to end users during deployments.
Why does Load Balancing matter?
Without load balancing, your application depends on a single server, creating a single point of failure. When that server crashes or traffic spikes, every user is affected. Load balancing eliminates this risk by distributing traffic, automating failover, and enabling horizontal scaling. For businesses, this means higher uptime, a better user experience under load, and the ability to add servers without downtime, directly contributing to customer satisfaction and revenue. Financially, load balancing enables auto-scaling: servers are provisioned only when needed and automatically removed during off-peak hours, significantly reducing monthly cloud costs. It also enables development teams to perform zero-downtime deployments, so updates go live without maintenance windows or planned downtime that drives customers away.
Common mistakes with Load Balancing
Health checks only ping port 80 or verify TCP is open while the application itself is deadlocked, so traffic keeps hitting effectively dead nodes. Sticky sessions are configured without expiration and permanently pin users to a single machine that cannot scale. Teams assume a load balancer automatically scales the database, while the data store remains the actual bottleneck. SSL termination is forgotten and every backend performs unnecessary expensive TLS handshakes. Connection draining is not configured, so in-flight requests are abruptly terminated during deployments. Server weights in weighted routing are never adjusted when capacity changes, leaving powerful machines underutilized while weaker ones are overloaded. Load balancer access logs omit upstream latency, making it impossible to identify slow backends from the balancer metrics alone.
What are some examples of Load Balancing?
- A news website using NGINX round-robin load balancing during breaking news to distribute traffic across ten application servers, serving millions of concurrent visitors without noticeable latency while auto-scaling automatically adds extra servers as the load continues to grow.
- A SaaS platform using AWS Application Load Balancer to route API requests to the correct microservice based on URL path and HTTP headers, with automatic health checks removing unhealthy containers from the pool within seconds and only re-adding them after successful recovery checks.
- An e-commerce site using weighted load balancing to gradually shift traffic to newer, more powerful servers during a migration while keeping old servers as a fallback.
- A video streaming service using least-connections load balancing to distribute transcoding jobs across GPU servers, ensuring no single machine is overloaded while others sit idle.
- A banking application combining IP-hash load balancing with WebSocket support so long-lived connections are consistently routed to the same backend for transaction integrity.
Related terms
Frequently asked questions
We work with this every day
The same expertise you are reading about, we put to work for clients across Europe.
See what we doRelated articles
Monolith vs Microservices: Start Simple or Scale from Day One?
Start monolithic and split when needed - or go microservices from day one? The architecture choice that shapes your scalability and team structure.
What Is an API? How Application Programming Interfaces Power Modern Software
APIs enable software applications to communicate through standardized protocols and endpoints, powering everything from payment processing and CRM integrations to real-time data exchange between microservices.
What Is SaaS? Software as a Service Explained for Business Leaders and Teams
SaaS (Software as a Service) delivers applications through the cloud on a subscription basis. No installations, automatic updates, elastic scalability, and secure access from any device make it the dominant software delivery model for modern organizations.
What Is Cloud Computing? Service Models, Architecture and Business Benefits Explained
Cloud computing replaces costly local servers with flexible, on-demand IT infrastructure delivered through IaaS, PaaS, and SaaS from providers like AWS, Azure, and Google Cloud. Learn how it works and why it matters for your business.