
What is RAG? - Explanation & Meaning
RAG grounds AI responses in real data by retrieving relevant documents before generation. This is the key to reliable, factual LLM applications in production.
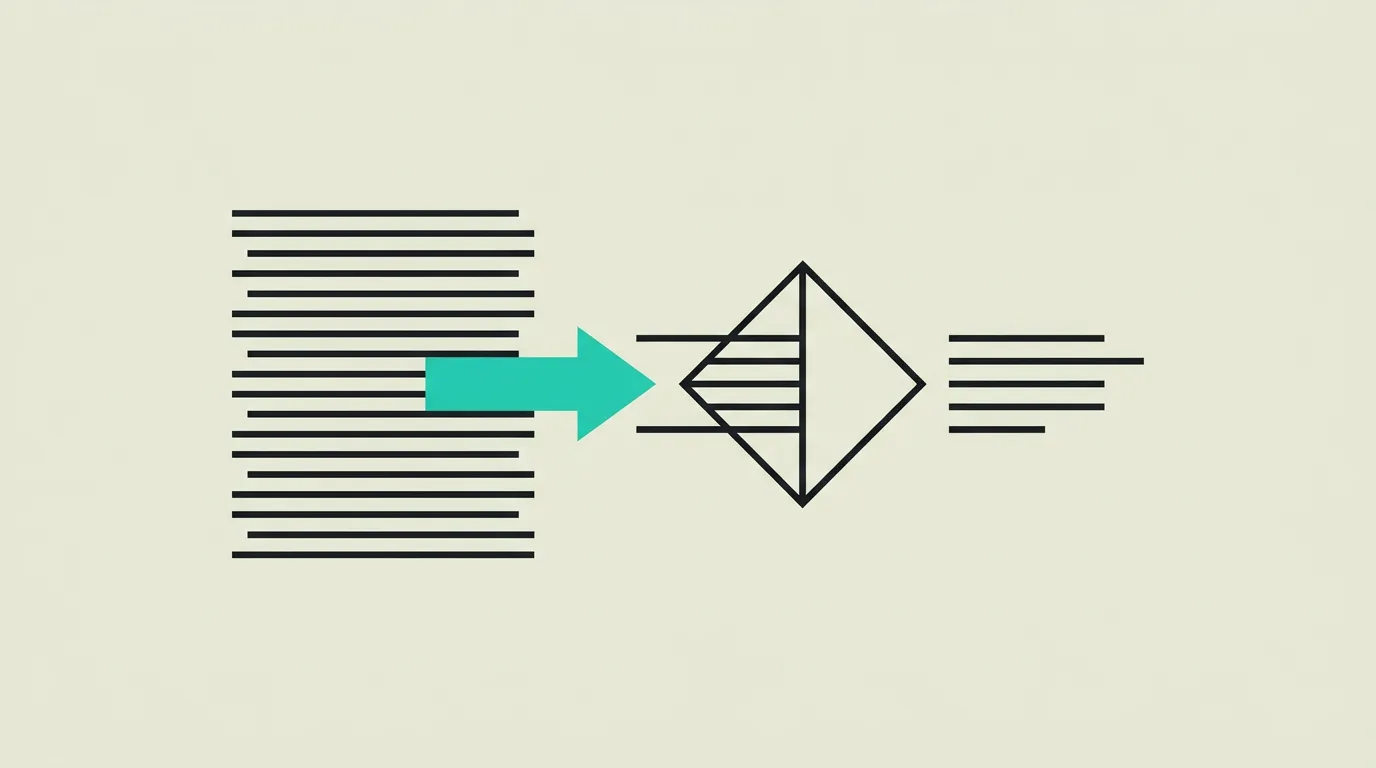
Retrieval-Augmented Generation (RAG) is an AI architecture pattern that supplements a large language model's knowledge by retrieving relevant information from external data sources before generating a response. Instead of relying solely on what the model learned during training, RAG searches a curated knowledge base in real time, injects the most relevant documents into the prompt context, and then generates an answer grounded in that retrieved evidence. This approach significantly reduces hallucinations and ensures output reflects current, verifiable data rather than potentially outdated training knowledge.
What is RAG?
Retrieval-Augmented Generation (RAG) is an AI architecture pattern that supplements a large language model's knowledge by retrieving relevant information from external data sources before generating a response. Instead of relying solely on what the model learned during training, RAG searches a curated knowledge base in real time, injects the most relevant documents into the prompt context, and then generates an answer grounded in that retrieved evidence. This approach significantly reduces hallucinations and ensures output reflects current, verifiable data rather than potentially outdated training knowledge.
How does RAG work technically?
RAG operates in three core phases: indexing, retrieval, and generation. During indexing, source documents are split into chunks using strategies that range from fixed-size windows to semantic chunking that respects natural paragraph and section boundaries. Each chunk is converted into a numerical vector representation (embedding) via an embedding model such as OpenAI text-embedding-3-large or Cohere Embed v4, and stored in a vector database like Pinecone, Weaviate, Qdrant, or pgvector. When a user query arrives, it is likewise embedded, and the most relevant chunks are retrieved via similarity search using cosine similarity or dot product metrics. Those chunks are injected into the LLM prompt as context, and the model generates a response based on both its parametric knowledge and the retrieved evidence. Advanced RAG implementations in 2026 go well beyond this basic pipeline. Hybrid search combines dense vector retrieval with sparse keyword matching (BM25) to capture both semantic similarity and exact term matches. Re-ranking models such as Cohere Rerank or cross-encoder architectures re-score retrieved chunks for improved precision before they reach the LLM. Query transformation techniques including query expansion, hypothetical document embeddings (HyDE), and multi-query decomposition help bridge the gap between how users phrase questions and how information is stored. Agentic RAG takes this further by letting an AI agent dynamically decide which data sources to consult, whether to refine the query, or when to combine results from multiple retrievals. Evaluation frameworks like RAGAS and custom metrics for faithfulness, relevance, and answer correctness allow teams to systematically measure and improve pipeline quality over time.
How does MG Software apply RAG in practice?
RAG is the standard architecture at MG Software for all AI solutions that require business-specific knowledge. We build end-to-end RAG pipelines that unlock internal documents, knowledge bases, databases, and API endpoints for AI consumption. Every implementation begins with a thorough data audit to understand document types, update frequencies, and quality levels. We select appropriate chunking strategies based on content structure and combine hybrid search with re-ranking to maximize retrieval precision. Our pipelines include automated evaluation using metrics like faithfulness, answer relevance, and context precision, giving clients measurable quality scores they can track over time. For organizations with strict data residency requirements, we deploy fully on-premise solutions using open-source embedding models and self-hosted vector databases. We also implement feedback loops where end-user ratings feed back into the system to continuously improve retrieval quality and identify knowledge gaps.
Why does RAG matter?
RAG bridges the gap between the powerful language capabilities of LLMs and the specific, current information that organizations need their AI systems to reference. Without RAG, an LLM can only draw on its training data, which may be months or years old and contains nothing about your internal processes, products, or customers. By connecting an LLM to your own knowledge base in real time, RAG makes it possible to build AI assistants that give accurate, source-backed answers about company-specific topics. This is particularly valuable in regulated industries where traceability matters: every answer can link back to the exact document it was derived from. As a result, RAG has become the foundational architecture for production AI applications across legal, healthcare, financial services, and enterprise knowledge management. RAG also provides a cost-effective alternative to fine-tuning for many knowledge-intensive use cases, since updating the knowledge base requires only re-indexing documents rather than retraining the model. This makes it especially practical for organizations whose information changes frequently, such as those managing evolving product catalogs, regulatory updates, or active support documentation.
Common mistakes with RAG
A common mistake is implementing RAG without sufficient attention to chunking strategy and embedding quality. Documents split at arbitrary positions lose context, producing chunks that are individually meaningless and lead to irrelevant retrievals. Equally problematic is choosing an embedding model without benchmarking it against your specific data. A model that performs well on general text may underperform on domain-specific terminology like legal or medical language. Many teams also skip evaluation entirely, deploying a RAG system without any systematic way to measure answer quality. Without metrics for faithfulness, relevance, and completeness, you cannot know whether changes improve or degrade performance. Finally, neglecting the data pipeline means stale or duplicated documents pollute the knowledge base over time. Schedule regular re-indexing, implement deduplication, and establish clear ownership over which documents enter the system. Teams that rely solely on vector similarity without incorporating hybrid search miss exact keyword matches for product codes, legal references, and technical identifiers that embedding models frequently fail to capture accurately. Combining BM25 keyword matching with dense vector retrieval through reciprocal rank fusion consistently improves recall in production systems.
What are some examples of RAG?
- An HR department implementing a RAG system that allows employees to ask natural language questions about company policies, benefits, and procedures, with answers always referencing the actual source documents.
- A technical support team deploying RAG to make a knowledge base of thousands of product manuals and troubleshooting guides searchable via an AI chatbot, reducing average resolution time by 45%.
- A legal department using RAG to retrieve relevant case law and statutory articles when drafting contracts, ensuring attorneys always work with the most current regulations.
- A pharmaceutical company using RAG to enable researchers to query thousands of clinical trial reports, patent filings, and regulatory submissions in natural language, with every AI-generated answer linking directly to the source paragraphs for verification and compliance documentation.
- An accounting firm deploying RAG across its tax advisory practice, allowing consultants to retrieve the latest rulings, precedents, and legislative updates from multiple jurisdictions when preparing client advice, ensuring recommendations always reflect current regulations.
Related terms
Frequently asked questions
We work with this every day
The same expertise you are reading about, we put to work for clients across Europe.
See what we doRelated articles
What is Generative AI? - Explanation & Meaning
Generative AI creates original text, images, and code from prompts, from LLMs like GPT and Claude to diffusion models for image generation.
What is Prompt Engineering? - Explanation & Meaning
Prompt engineering is the craft of writing effective AI instructions, using techniques like chain-of-thought, few-shot, and system prompting.
What is a Vector Database? - Explanation & Meaning
Vector databases store embeddings and perform lightning-fast similarity searches, essential for RAG, semantic search, and modern AI applications.
Chatbot Implementation Examples - Inspiration & Best Practices
Handle 70% of customer inquiries without human agents. Chatbot implementation examples for telecom, HR self-service, product advice, and appointment booking.